
Synthetic identity fraud doesn't look like traditional fraud. There's no stolen credit card, no hacked account, no obvious red flag. Instead, a fraudster stitches together a fictional person, part real Social Security number, part fabricated name and address, and patiently builds a credit history before executing a "bust-out" that drains lenders of thousands of dollars overnight.
It's a slow, precise attack, and it's winning. Traditional rule-based fraud systems, the kind that check a single data point against a blocklist, are almost completely blind to it. The solution lies in machine learning: pattern recognition at a scale and depth no human analyst can replicate.
~ $20B+ : Annual losses to synthetic identity fraud in the US alone. Source: Federal Reserve, 2023
~ 85% : Of financial institutions report increasing synthetic fraud attacks year-over-year. Source: LexisNexis Risk Solutions, 2024
~ 3 yrs : Average time a synthetic identity is "nurtured" before a bust-out event.
Source: Auriemma Consulting Group
What Makes Synthetic Identity Fraud So Hard to Catch
A synthetic identity is designed to pass every individual check. The SSN may belong to a child, a recent immigrant, or a deceased person — groups with thin or no credit files. The fraudster adds fabricated name, date of birth, and address, then applies for secured credit cards and small loans. They pay on time. They build a score. They get a limit increase. Then they vanish.
The problem is that each individual data point looks legitimate. Rule-based systems ask binary questions: "Is this SSN valid? Yes. Is this address real? Yes." They pass the synthetic identity every time. What they can't see is the relationship between signals and that's exactly what machine learning excels at.
"Synthetic identity fraud is the perfect crime for the rule-based era. Machine learning is what ends it."
The ML Detection Stack: How It Actually Works
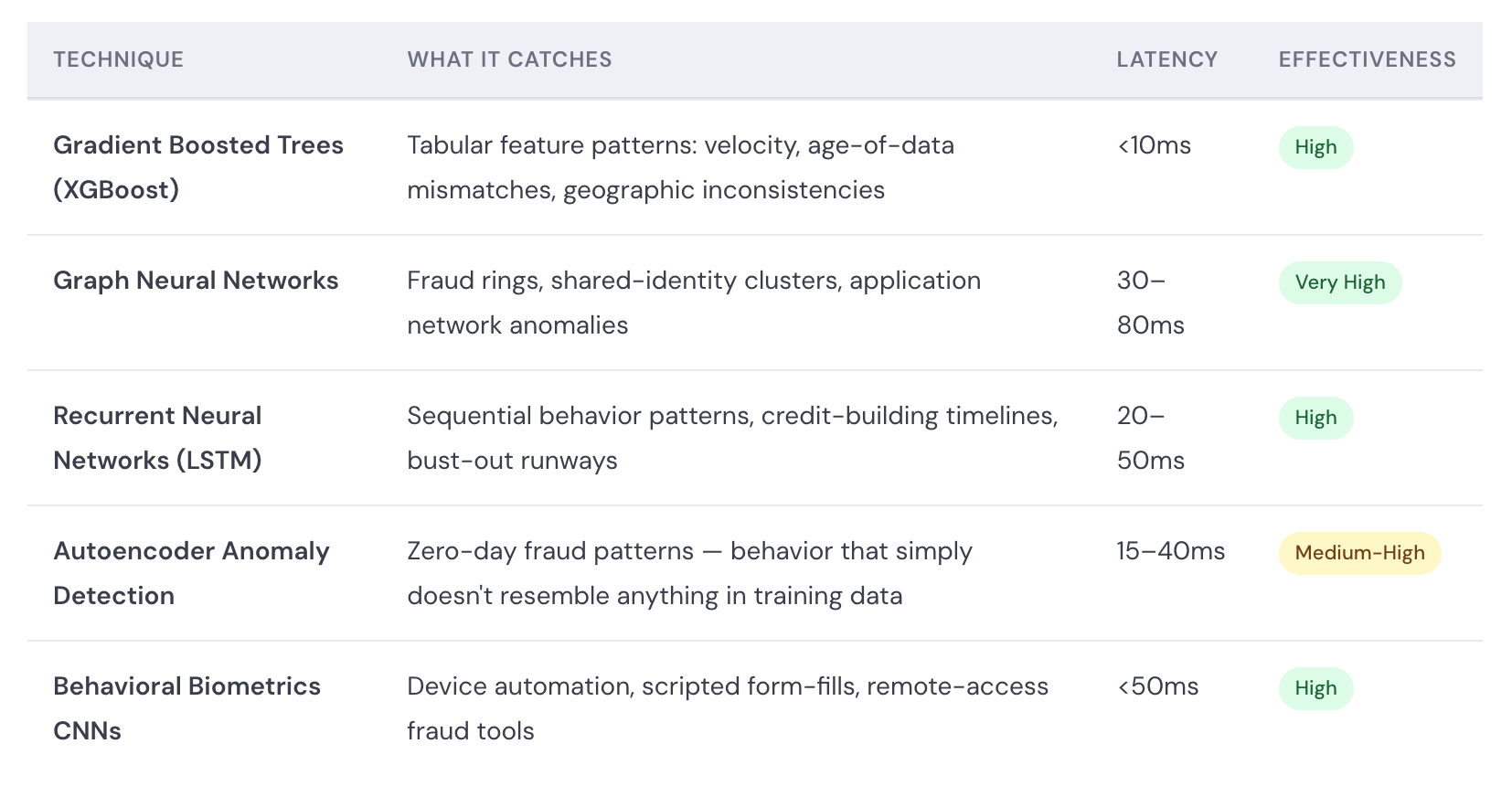
Modern real-time fraud detection isn't a single model, it's a layered system of specialized algorithms, each attacking the problem from a different angle. Here's how the stack is built.

1. Graph Neural Networks (GNNs): Finding the Hidden Web The most powerful advance in synthetic identity detection is the application of graph neural networks. Every identity — real or synthetic — leaves a web of connections: shared phone numbers, overlapping addresses, the same device used to apply for multiple accounts, IP addresses clustering around the same subnet.
GNNs map these relationships as nodes and edges in a graph, then learn which connection patterns are statistically associated with fraud. A single synthetic identity may look clean in isolation, but when the GNN sees that its phone number links to 47 other accounts opened in the past 90 days, the fraud score spikes immediately.
2. Behavioral Biometrics: The Way You Type Is Your Fingerprint Fraudsters filling out applications behave differently from legitimate users. They paste data rather than type it. They move the mouse in straight lines. They complete forms at machine speed. Behavioral biometrics models — trained on millions of real user sessions — detect these micro-patterns in real time, flagging sessions that match bot or fraud-rig profiles even when the identity data itself is clean.
3. Device Intelligence: Every Device Has a Story A synthetic identity needs a device to operate. Device intelligence platforms fingerprint every hardware and software signal — screen resolution, installed fonts, GPU characteristics, battery state, network stack anomalies — and cross-reference them against known fraud devices. Emulators, rooted devices, and VPN tunnels used to mask location all produce distinct signatures that ML models identify with high confidence.

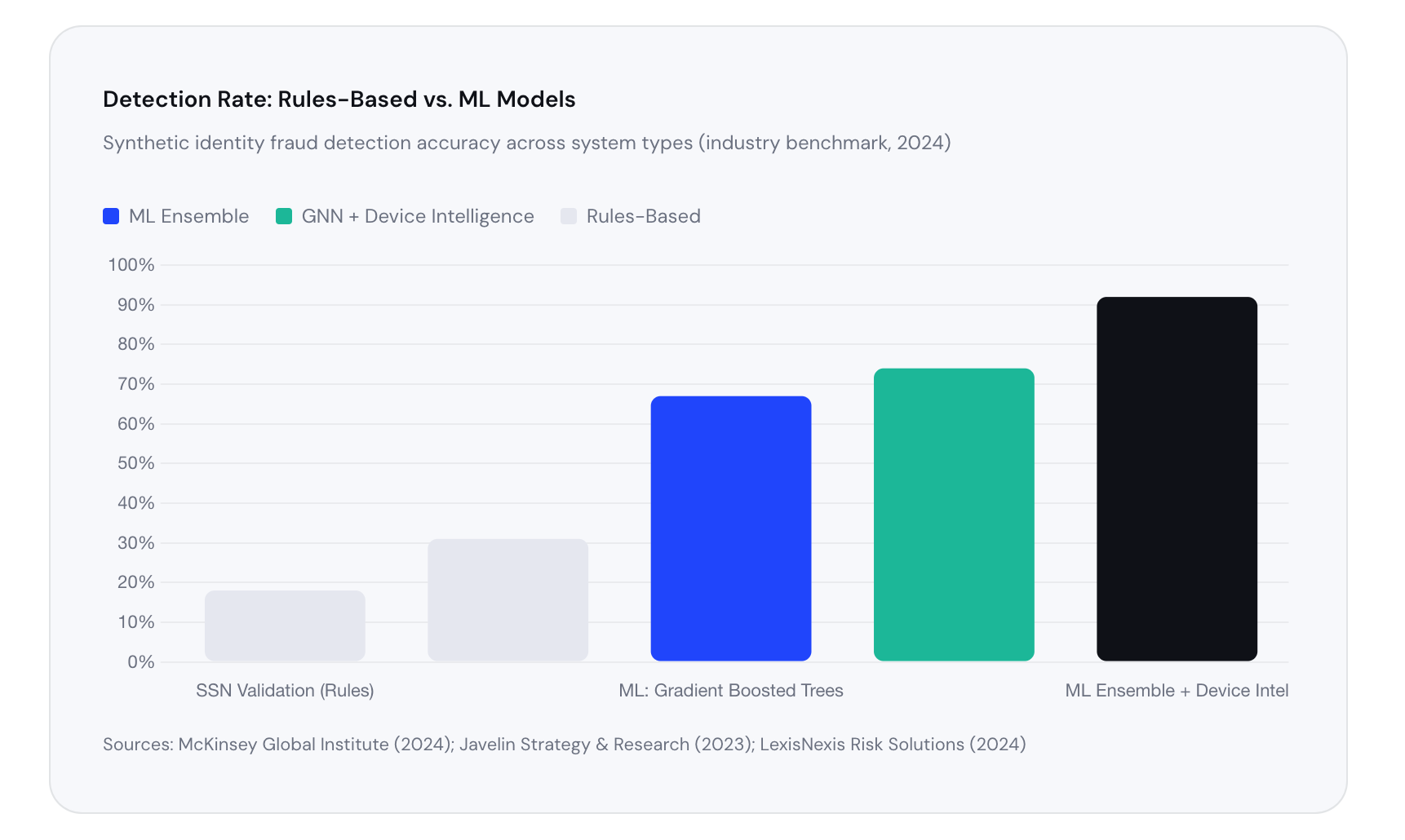
The Model Architecture: Ensemble Methods Win
No single algorithm catches everything. The industry standard is now ensemble modeling — combining multiple ML approaches so their weaknesses cancel out and their strengths compound.
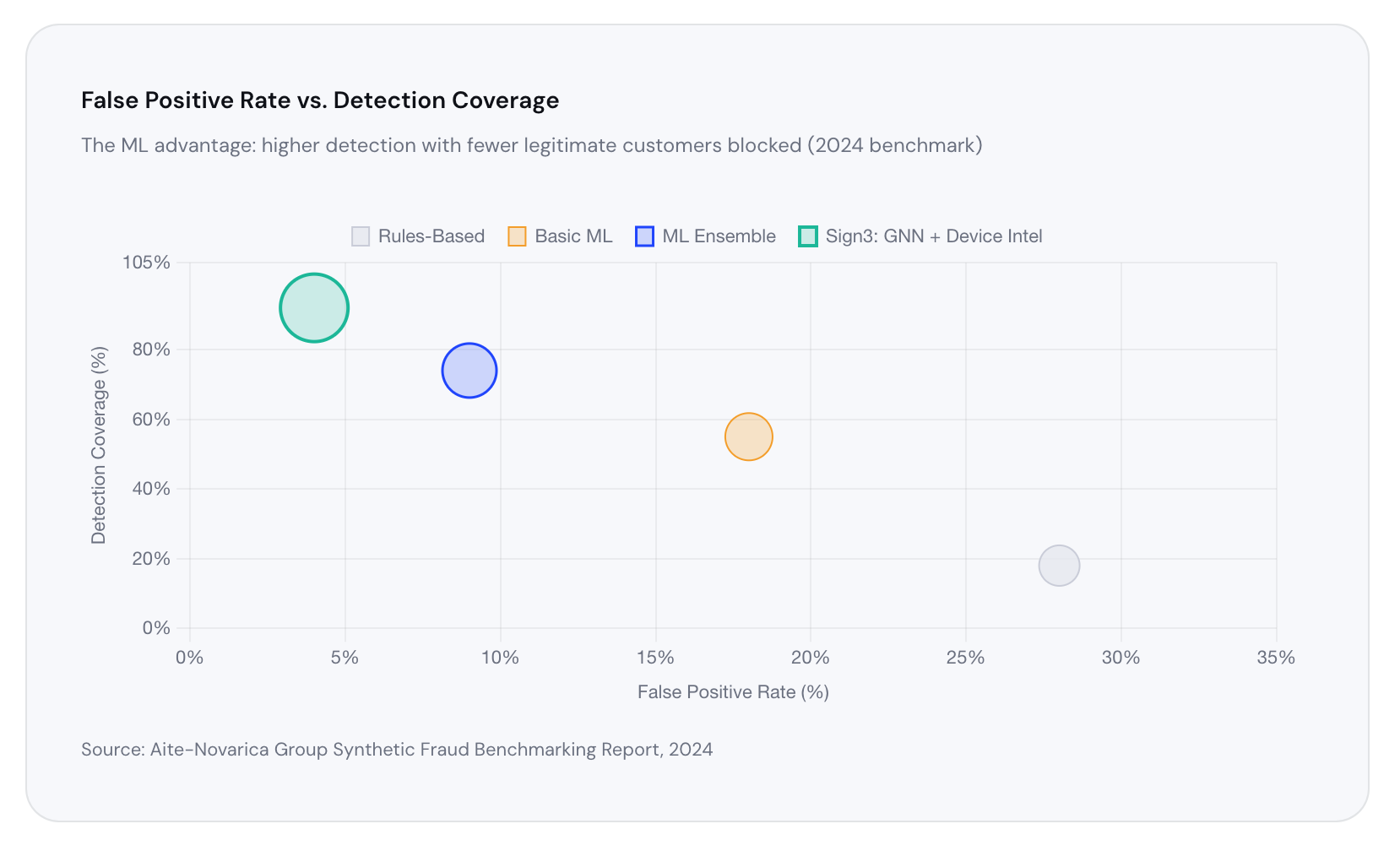
Real-Time Scoring: Sub-200ms Decisions at Scale
The challenge of ML fraud detection isn't just accuracy — it's speed. A model that takes 10 seconds to score an application creates friction that drives customers away. The industry standard is now sub-200 milliseconds, end to end: signal capture, feature computation, model inference, and decision delivery, all before the user finishes clicking "submit."
Achieving this requires careful engineering: pre-computed graph embeddings stored in low-latency vector databases, quantized model weights deployed on GPU-accelerated inference servers, and streaming feature pipelines that compute velocity features in real time against distributed counters rather than batch database queries.
This is where device intelligence becomes especially powerful. An SDK embedded at the app layer can compute behavioral and device features locally — before the application is even submitted — so the fraud score is ready the moment the request hits the server.
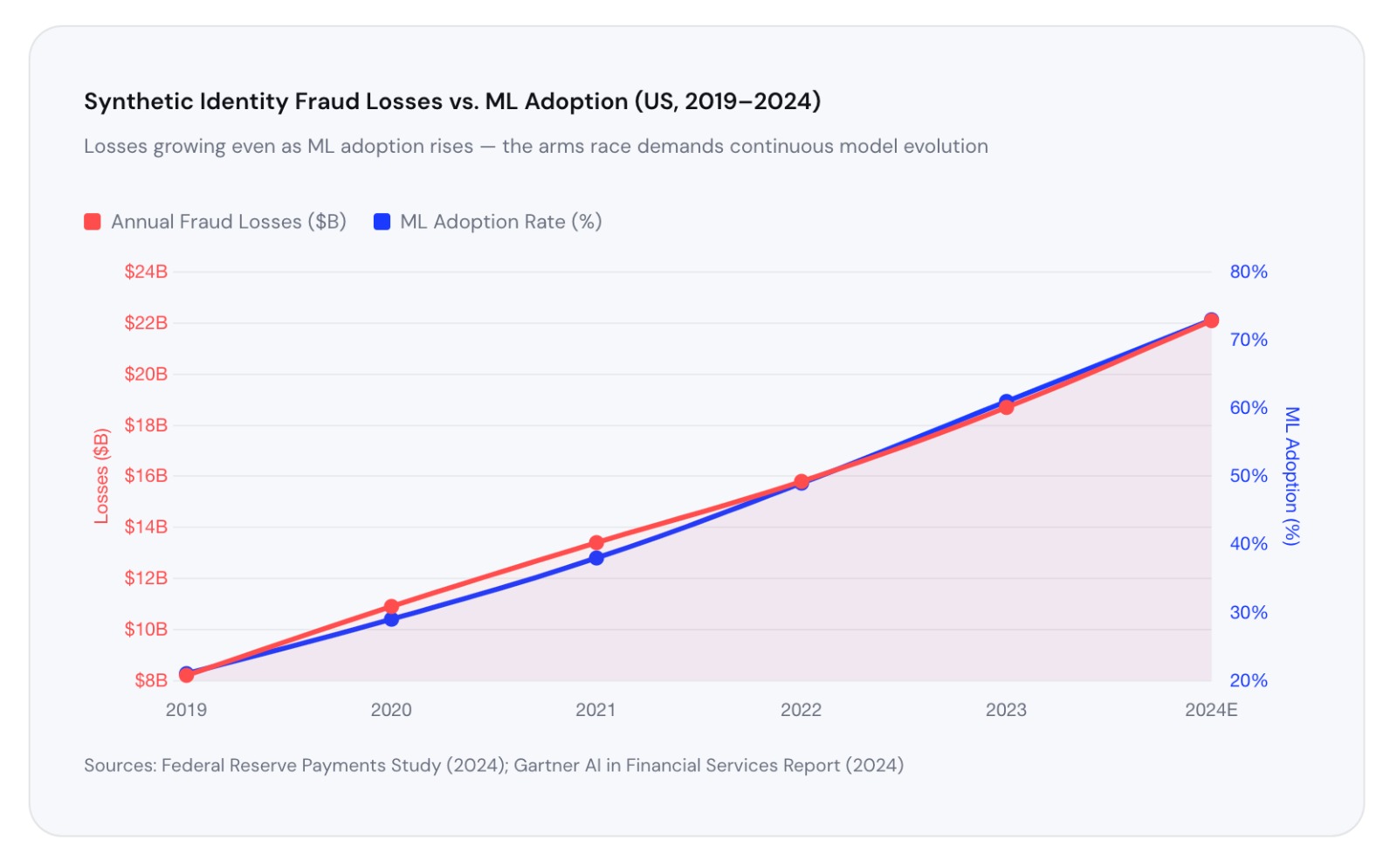
The Continuous Learning Loop: Staying Ahead of Evolving Fraud
Fraud is not static. Fraud rings adapt, probe defenses, and update their tactics in response to what gets blocked. A model trained in 2022 may be significantly degraded by 2024 as attacker behavior evolves. This is why the best ML systems are built on a closed feedback loop.
Every confirmed fraud case becomes a training label. Every account that executes a bust-out, every device fingerprint linked to a known fraud ring, every behavioral session that matches confirmed bot activity — all of it flows back into model retraining pipelines. In leading systems, models are retrained on rolling windows of data, with concept drift detection algorithms triggering retraining automatically when the fraud population shifts.
"The best fraud model is never the one you trained last year. It's the one you're training today, on yesterday's attacks."
What "Real Time" Actually Requires
Genuine real-time detection — not batch scoring, not next-day flagging — requires four components working in concert. First, a device intelligence layer that begins scoring the moment the session opens, not when the application is submitted. Second, a streaming feature store that computes velocity and graph features in milliseconds against live data. Third, an inference infrastructure capable of serving model predictions at <50ms P99 latency even at peak application volumes. And fourth, a decisioning engine that translates scores into actions — approve, decline, or step-up to additional verification — without human intervention.
This architecture is what separates fraud platforms that catch synthetic identities at origination from those that discover them months later during charge-off analysis. By then, the bust-out has already happened.
The Sign3 Approach
Sign3's device intelligence platform is built for exactly this challenge. By embedding a lightweight SDK directly into the application layer, Sign3 captures over 300 device, behavioral, and network signals before a single form field is submitted. These signals feed into ensemble ML models — combining gradient boosted trees, behavioral biometrics classifiers, and device fingerprint anomaly detectors — to produce a unified fraud risk score in under 150 milliseconds.
The result: financial institutions using Sign3 detect synthetic identities at origination, not at charge-off — reducing fraud losses while maintaining the fast, frictionless experience that genuine customers expect.
About The Author

Amit Chahal is the co-founder and Data Science head at Sign3, brings over a decade of experience in machine learning and financial fraud solutions, transforming how businesses safeguard against risks.